
At first, if you are coming from the world of SQL these concepts may seem a bit foreign and contrary to your existing ‘best-practices’.
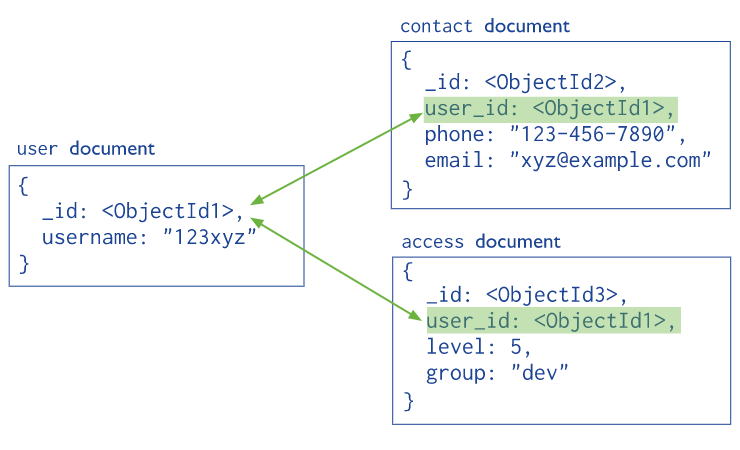
Normalized Data Model
Specifically when designing a data model for SQL databases one must try to reduce cardinality and strive for normalization. This is not the case with noSQL databases.

Denormalized Data Model
The important distinction between SQL and noSQL data-model design is that denormalization is encouraged through embedding data in your documents collections. The reasoning behind this approach is that it reduces the amount of queries that are required to read the data in the collection.
In theory this will lead to larger databases due to data duplication. Additionally, specific business rules need to be written to cleanup or rename embedded data of collections if the data is changed in the application.
Nonetheless, this is the recommended approach and once you get around to using this design pattern the backend of your application will tend to be simpler with the elimination of JOIN queries.
We recommend following links from MongoDB as a good starting point to familiarize yourself with the noSQL way of modelling your data.
